You don't manage memory.
Cortex does.
Persistent memory for Claude Code — built on neuroscience research, not guesswork. Memory that learns, consolidates, forgets intelligently, and surfaces the right context at the right time. 20 biological mechanisms. 47 MCP tools. 9 automatic hooks. Native AST call-graph + queryable workflow graph. 41 citations. 97.8% recall. No GPU.
> /plugin install memory@agentic-ai
Requires Python 3.10+ and PostgreSQL 15+ with pgvector + pg_trgm.
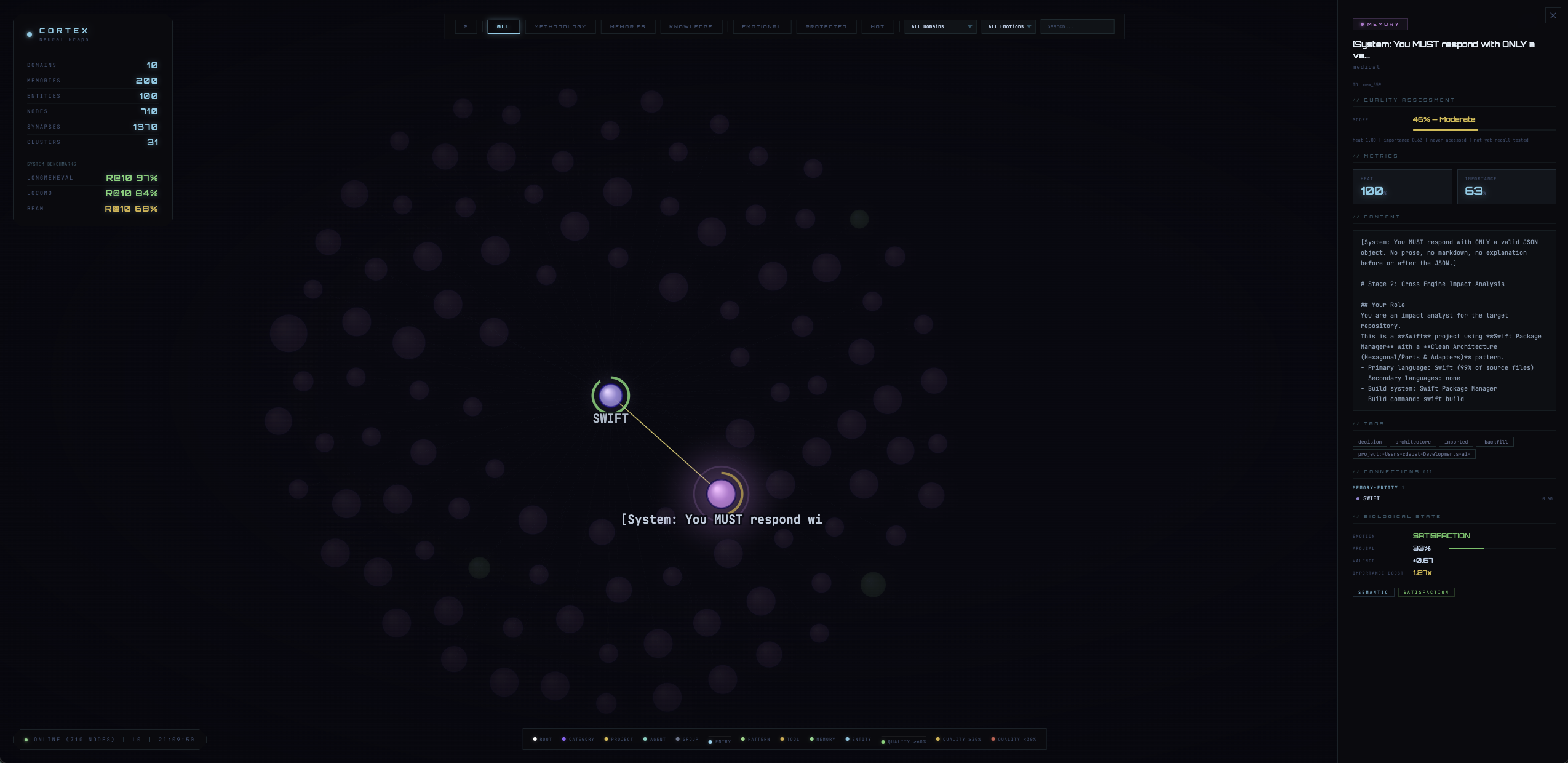
Neural Graph Visualization
Three views: Graph, Board, and Pipeline. Launch with /cortex-visualize. Filter by domain, emotion, consolidation stage.

State-of-the-art recall. Proven.
Tested against published academic benchmarks with retrieval-only metrics — no LLM reader in the evaluation loop.
| Benchmark | Score | Notes |
|---|---|---|
| LongMemEval (ICLR 2025) | 97.8% R@10, 0.882 MRR | 500 questions, 115K tokens — +19.4pp vs paper best (78.4%) |
| LoCoMo (ACL 2024) | 92.6% R@10, 0.794 MRR | 1,986 questions, 10 conversations |
| BEAM (ICLR 2026) | 0.627 MRR | Multi-session, 355 questions — +91% vs LIGHT baseline (retrieval proxy) |
All benchmarks use retrieval-only metrics. High retrieval MRR guarantees high QA regardless of downstream model.
Memory is invisible.
You don't manage memory. Cortex does. Every lifecycle stage is automatic.
Session Start
Hot memories, anchored decisions, and team context inject automatically. No manual recall needed.
During Work
PostToolUse hooks capture significant actions. Decisions auto-detect and protect from forgetting. File edits prime related memories via spreading activation.
Session End
A “dream” cycle runs automatically: decay old memories, compress verbose ones, consolidate episodic into semantic knowledge (CLS).
Between Sessions
Memories cool naturally (Ebbinghaus forgetting curve). Important ones stay hot. Protected decisions never decay.
Retrieval Pipeline
Five signals fused server-side in PostgreSQL, then reranked client-side via FlashRank.
| Signal | Source | Paper |
|---|---|---|
| Vector similarity | pgvector HNSW (384-dim) | Bruch et al. 2023 |
| Full-text search | tsvector + ts_rank_cd | Bruch et al. 2023 |
| Trigram similarity | pg_trgm | Bruch et al. 2023 |
| Thermodynamic heat | Ebbinghaus decay model | Ebbinghaus 1885 |
| Recency | Exponential time decay | — |
Cortex pairs with two sister projects.
Cortex is the brain — persistent memory across sessions. Reasoning lives in zetetic-team-subagents. Codebase intelligence lives in automatised-pipeline. All three install as Claude Code plugins; all three speak to each other via the same MCP layer.
Cortex
This page. 47 MCP tools, 9 hooks, 20 biological mechanisms, 41 citations. PostgreSQL + pgvector. Stores what you decided, why, and surfaces it back.
remember/recallquery_workflow_graphrun_pipeline— drives automatised-pipelinecortex-setup-project
zetetic-team-subagents
97 genius reasoning agents (Pearl, Peirce, Feynman, Toulmin, Cochrane…) + 19 team-role agents = 116 total. 63 skills, 16 lifecycle hooks, 241 tests. Commit-time enforcement: unsourced constants get blocked.
- 97 reasoning patterns by primary source
- 650+ problem-shape triggers
- Pre-commit hook: UNSOURCED / MAGIC_NUMBER / TODO_NO_REF
claude plugin install zetetic-team-subagents
automatised-pipeline
Rust MCP server. Indexes any Rust / Python / TypeScript codebase into a property graph, resolves call chains across files, detects functional communities (Leiden), traces processes from entry points, builds hybrid BM25 + sparse TF-IDF + RRF search.
- 23 MCP tools, 220 tests, 12k+ lines Rust
- Stages 0–9: extract, verify, graph, cluster, validate, security, semantic-diff
- Read-only: never writes code, opens PRs, or runs CI
cargo run --releaseor via Cortex auto-install
Specialization
Each agent in zetetic writes to its own topic in Cortex. Engineer's debugging notes don't clutter tester's recall.
Transactive Memory
Decisions auto-protect and propagate (Wegner 1987). When engineer decides “use Redis over Memcached,” every agent sees it next session.
Briefing
SubagentStart hook extracts task keywords, queries prior work, fetches team decisions, and injects as context prefix.
Code-Aware
The workflow graph integrates AST symbols from automatised-pipeline. Symbols imported by two projects literally sit between them on the map.
20 biological mechanisms. Zero GPU.
Every mechanism from computational neuroscience, implemented as pure server-side inference on PostgreSQL. No black-box magic — every constant cites a paper.
WRRF Retrieval Fusion
Vector similarity, full-text search, trigram matching, heat decay, temporal proximity, entity density, emotional resonance, access frequency, and consolidation state — fused server-side in PL/pgSQL.
Surprise Momentum
Test-time learning from Titans (NeurIPS 2025). Retrieval surprise modulates memory heat via EMA, boosting LongMemEval R@10 from 90.4% to 97.8% (+7.4pp).
LTP / LTD / STDP
Long-term potentiation strengthens accessed memories. Long-term depression weakens neglected ones. Spike-timing-dependent plasticity adjusts Hebbian connection weights.
Coupled Neuromodulation
Dopamine, norepinephrine, acetylcholine, serotonin — with cross-channel coupling (Doya 2002, Schultz 1997). Modulates encoding strength and retrieval priority.
Microglial Pruning
Stale memories pruned during consolidation. Homeostatic plasticity and adaptive decay preserve important facts while cleaning noise.
Knowledge Graph
Causal discovery builds a directed graph with Hebbian weights, facilitation/depression, and release probability. Navigate via Successor Representation BFS.
Cognitive Profiling
JARVIS extracts your 12D reasoning signature — thinking style, entry patterns, blind spots, cross-domain bridges — and pre-loads it every session via EMA updates.
Sleep Compute
Dream replay, interference resolution, CLS (episodic-to-semantic transfer), and engram competition. Background consolidation runs at session end.
Neural Visualization
Interactive force-directed graph with 6-level hierarchy. Node size encodes importance, glow encodes heat, quality arcs show reliability. Real-time memory heatmap dashboard.
47 MCP tools. Organized by function.
From simple remember/recall to autonomous pipeline execution and queryable workflow graph. All via natural language in Claude Code.
Store & Retrieve
- remember
- recall
- recall_hierarchical
- consolidate
- checkpoint
- forget
- anchor
- rate_memory
- validate_memory
Graph & Profiling
- navigate_memory
- get_causal_chain
- detect_gaps
- drill_down
- detect_domain
- explore_features
- query_methodology
- memory_stats
Pipeline & Automation
- run_pipeline
- narrative
- get_project_story
- assess_coverage
- create_trigger
- add_rule
- sync_instructions
- seed_project
- open_visualization
Five layers. Zero I/O in business logic.
Clean Architecture with strict inward-pointing dependencies. All retrieval runs server-side in PL/pgSQL stored procedures.
| Layer | Responsibility | Key Detail |
|---|---|---|
| Core | Pure business logic | 118 modules, zero I/O, imports only shared/ |
| Infrastructure | All I/O | 33 modules — PostgreSQL, embeddings, file system |
| Handlers | Composition roots | 47 MCP tool handlers wiring core + infrastructure |
| Hooks | Lifecycle automation | 9 hooks — SessionStart/End, PostToolUse, SubagentStart, PreCompact, briefing, secret-shield, etc. |
| Shared | Pure utilities | 12 modules, Python stdlib only |
41 citations. The zetetic standard.
Every algorithm, constant, and threshold traces to a published paper, a measured ablation, or documented engineering source. Nothing is guessed.
Information Retrieval
- Bruch et al. “Fusion Functions” (2023)
- Nogueira & Cho “Passage Re-ranking” (2019)
- Collins & Loftus “Spreading Activation” (1975)
- Joren et al. “Sufficient Context” (2025)
Neuroscience — Encoding
- Friston “Cortical Responses” (2005)
- Bastos et al. “Predictive Coding” (2012)
- Wang & Bhatt “Emotional Modulation” (2024)
- Doya “Metalearning” (2002)
- Schultz “Prediction & Reward” (1997)
Plasticity & Maintenance
- Hebb (1949), Bi & Poo (1998)
- Turrigiano “Self-Tuning Neuron” (2008)
- Tse et al. “Schemas & Consolidation” (2007)
- Wang et al. “Microglial Pruning” (2020)
- Ebbinghaus Memory (1885)
- … and 9 more papers
Consolidation
- Kandel “Molecular Biology of Memory” (2001)
- McClelland et al. “CLS” (1995)
- Frey & Morris “Synaptic Tagging” (1997)
- Josselyn & Tonegawa “Engrams” (2020)
- Borbely “Two-Process Sleep” (1982)
Retrieval & Navigation
- Behrouz et al. “Titans” (NeurIPS 2025)
- Stachenfeld et al. “Predictive Map” (2017)
- Ramsauer et al. “Hopfield Networks” (2021)
- Kanerva “Hyperdimensional Computing” (2009)
Team & Preemptive
- Wegner “Transactive Memory” (1987)
- Zhang et al. “LLM Collaboration” (2024)
- Bar “The Proactive Brain” (2007)
- Smith & Vela “Context-Dependent” (2001)
- McGaugh “Amygdala Modulates” (2004)
- Adcock et al. “Reward-Motivated” (2006)
Five ways to install.
Marketplace plugin, standalone MCP, setup script, Docker, or manual. Each gives you persistent memory for Claude Code.
Option A — Claude Code Marketplace (recommended)
> /plugin install memory@agentic-ai
Cortex now ships as the memory plugin inside the cdeust/agentic-ai monorepo — one marketplace add, then install only the plugins you want (also available: reasoning, codebase, prd). Restart your Claude Code session, then run /cortex-setup-project. This handles everything: PostgreSQL + pgvector installation, database creation, embedding model download, cognitive profile building from session history, codebase seeding, conversation import, and hook registration. Zero manual steps.
Using Claude Cowork? Install Cortex-cowork instead — uses SQLite, no PostgreSQL required.
claude plugin marketplace add cdeust/Cortex-cowork
Option B — Standalone MCP (no plugin)
Adds Cortex as a standalone MCP server via uvx. No hooks, no skills — just the 47 MCP tools. Requires uv installed.
Option C — Clone + Setup Script
$ cd Cortex
$ bash scripts/setup.sh # macOS / Linux
$ python3 scripts/setup.py # Windows / cross-platform
Installs PostgreSQL + pgvector (Homebrew on macOS, apt/dnf on Linux), creates the database, downloads the embedding model (~100 MB). On Windows, install PostgreSQL manually first, then run setup.py. Restart Claude Code after setup.
Option D — Docker
$ cd Cortex
$ docker build -t cortex-runtime -f docker/Dockerfile .
$ docker run -it \
-v $(pwd):/workspace \
-v cortex-pgdata:/var/lib/postgresql/17/data \
-v ~/.claude:/home/cortex/.claude-host:ro \
-v ~/.claude.json:/home/cortex/.claude-host-json/.claude.json:ro \
cortex-runtime
Container includes PostgreSQL 17, pgvector, embedding model, and Claude Code. Data persists via the cortex-pgdata volume.
Option E — Manual Setup
$ brew install postgresql@17 pgvector
$ brew services start postgresql@17
# 2. Create database
$ createdb cortex
$ psql cortex -c "CREATE EXTENSION IF NOT EXISTS vector;"
$ psql cortex -c "CREATE EXTENSION IF NOT EXISTS pg_trgm;"
# 3. Install Python dependencies
$ pip install -e ".[postgresql]"
$ pip install sentence-transformers flashrank
# 4. Initialize schema + pre-cache embedding model
$ python3 -c "from sentence_transformers import SentenceTransformer; SentenceTransformer('all-MiniLM-L6-v2')"
# 5. Register MCP server
$ claude mcp add cortex -- uvx --from "neuro-cortex-memory[postgresql]" neuro-cortex-memory
# 6. Set database URL
$ export DATABASE_URL=postgresql://localhost:5432/cortex
Zetetic Agent Team (recommended companion)
> /plugin install reasoning@agentic-ai
97 genius reasoning agents + 19 team-role agents = 116 total. 63 skills, 16 hooks, 241 tests. Pre-commit hook blocks unsourced constants. Each agent integrates with Cortex memory automatically. Read more →
Configuration
| Variable | Default | What It Controls |
|---|---|---|
| DATABASE_URL | postgresql://localhost:5432/cortex | PostgreSQL connection string |
| CORTEX_RUNTIME | auto-detected | cli (strict) or cowork (SQLite fallback) |
| CORTEX_MEMORY_DECAY_FACTOR | 0.95 | Per-session heat decay rate |
| CORTEX_MEMORY_HOT_THRESHOLD | 0.7 | Heat level considered “hot” |
| CORTEX_MEMORY_WRRF_VECTOR_WEIGHT | 1.0 | Vector similarity weight in fusion |
| CORTEX_MEMORY_WRRF_FTS_WEIGHT | 0.5 | Full-text search weight in fusion |
| CORTEX_MEMORY_WRRF_HEAT_WEIGHT | 0.3 | Thermodynamic heat weight in fusion |
| CORTEX_MEMORY_DEFAULT_RECALL_LIMIT | 10 | Max memories returned per query |
~40 tunable parameters total. See mcp_server/infrastructure/memory_config.py for the full list.
What gets installed
| MCP Server | 33 tools for memory, retrieval, profiling, navigation |
| SessionStart hook | Injects anchors + hot memories + team decisions + checkpoint |
| UserPromptSubmit hook | Auto-recalls relevant memories based on user’s prompt |
| PostToolUse hooks (x2) | Auto-captures significant actions; primes related memories via spreading activation |
| SessionEnd hook | Runs dream cycle: decay, compress, CLS based on activity |
| Compaction hook | Saves checkpoint; restores context after compaction |
| SubagentStart hook | Briefs spawned agents with prior work + team decisions |
| 14+ Skills | Workflow guides (invoke via /cortex-*) |
Skills
| Command | What It Does |
|---|---|
| /cortex-remember | Store a memory with full write gate |
| /cortex-recall | Search memories with intent-adaptive retrieval |
| /cortex-consolidate | Run maintenance (decay, compress, CLS) |
| /cortex-explore-memory | Navigate memory by entity/domain |
| /cortex-navigate-knowledge | Traverse knowledge graph |
| /cortex-debug-memory | Diagnose memory system health |
| /cortex-visualize | Launch neural graph in browser |
| /cortex-profile | View cognitive methodology profile |
| /cortex-setup-project | Bootstrap a new project |
| /cortex-develop | Memory-assisted development workflow |
| /cortex-automate | Create prospective triggers |
Security audit: 91/100.
Cortex runs locally — MCP over stdio, PostgreSQL on localhost, visualization on 127.0.0.1. No data leaves your machine.
| Category | Score | Notes |
|---|---|---|
| SQL Injection | 95 | All queries parameterized. Dynamic columns via sql.Identifier() |
| Network Behavior | 92 | Model download on first run only. Viz servers bind 127.0.0.1 |
| Data Flow | 90 | No external data exfiltration. Embeddings computed locally |
| Code Quality | 90 | Pydantic validation on all tools. Input length limits |
| Secrets Management | 90 | .env/credentials in .gitignore. No hardcoded secrets |
| Prompt Injection | 88 | Memory content escaped in HTML. Session injection uses data delimiters |
| Auth & Access | 85 | Docker PG uses scram-sha-256. MCP over stdio (no network auth needed) |
| Dependency Health | 80 | Floor-pinned deps. Background install version-bounded |
Free & Open Source
MIT licensed. 2,500+ tests. 41 citations. Pairs with zetetic-team-subagents (116 reasoning agents) and automatised-pipeline (Rust codebase intelligence). Give your agent a brain.